We propose in this section a conceptual model for hypervideos, so that
they can be created, stored and shared.
Our model is composed of two-layers. The first layer, named core
model, aims at being general enough to match a number of uses, as
independently as possible from technological evolutions. The second
layer, named applicative model, specialises the core model through a
number of technical decisions that make it directly
implementable. Multiple applicative models can be proposed over the
core model, but the Cinelab project aims at finding a common
applicative model that can be useful for many partners/uses.
This section focuses on the core model, indicating the points that
need to be more precisely specified in the applicative model.
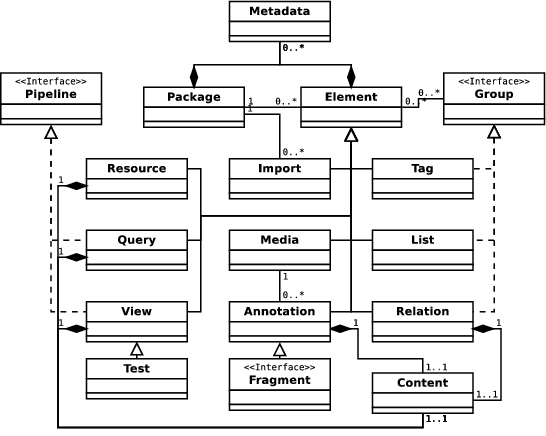
General points
Package
The package is the documentary unit of the hypervideo model. It
contains a set of elements, linked through different relations (see
below).
A package can be identified by a URI, that can identify it
persistently (independently from the way it was obtained). When a
package does not have a URI, it is identify through the URL used to
access it.
Elements
All elements in a package are uniquely identified by a character
string composed of alphanumerical characters, dashes, underscores and
colons (:), matching the following regular expression:
^([a-zA-Z_][a-zA-Z0-9_\-]*|:[a-zA-Z0-9_:\-]*)$
NB: if a colon (:) is used in an identifier, then the identifier
MUST begin with :. This constraint is necessary for the
correct handling of dynamic imports (see section Dynamic import).
Each element belongs to an element type, among those defined in
section Elements. Two elements, even of different types, cannot have
the same id in the same package.
If an applicative model wants to define a specific (internal) role for
an element, it should use for this element an id starting with
:. Applications should not allow users to use ids starting with
: other than those defined by applicative models.
An element id can be used as a fragment on the package URI, in order
to identify the element from out of the package. Given a package whose
URI is http://advene.org/packages/example1.czp, containing an
element with id a1. This element can be addressed (outside of the
package) with the following URI:
http://advene.org/packages/example1.azp#a1
Content
In the following text, we call content an octet string with a MIME
type. The MIME type describes how the octet string should be interpreted.
A content can also optionaly be declared as conforming to a model (for
instance, XML schema, Relax NG, JSON-schema, etc). The model itself
should in this case be store in a package resource (see below) and
the content will reference this resource. The validation of the
content with respect to its model depends on the model MIME type. A
list of valid MIME types for models (for instance
application/relax-ng-compact-syntax or
application/schema+json) should be specified by applicative
models.
Element type
This section describes the various element types that can be part of a
package. There are roughly three kinds of types: those related to the
annotation structure (media, annotation, relation), those related to
the package structure (lists, tags, queries, dynamic imports) and
those related to annotation presentation (views, resources). Some
element types can provide common interfaces. These abstrac
interfaces (group, pipeline) are also presented.
Group(interface)
An element matches the group interface if it defines a subset of its
package’s elements. A group allows to enumerate all its elements, as well
as its elements matching a given type. Applicative models can define
a specific order with which some element types instances should be
enumerated (for instance, chronological order for annotations).
Pipeline (interface)
An element matches the pipeline interface if it takes an element or
a package as input, and outputs an element or a package. The output
element can be an pre-existing package element, or a generated element.
Applicative models can specify an integrity constraint mechanism
indicating on which elements a pipeline can apply. This mechanism can
use Test views as defined below.
Annotation
An annotation is composed of a content, linked to an audiovisual media
fragment. The fragment is made essentially of three elements: the id
of the annotated media, a start timecode and an end timecode. Temporal
bounds are expressed by integers, expressing units specified by the
Media element.
Some applications may need audiovisual fragments more complex than a
simple temporal interval: spatial-temporal interval, MPEG-4 object,
audio track specification (for a DVD), etc. For these scenarios, the corresponding
applicative model will specify metadata to augment the annotation
with, in order to constrain the annotated fragment with appropriate
information.
A specificity of the model is that the fragment element is not
separate from the annotation: each annotation intrisically defines the
media and temporal interval its is linked to. Other approaches
commonly define fragment elements independently from the annotations,
so that a single fragment instance can be linked to multiple
annotations. In our model, annotations are independent (time-speaking)
one from another: a fragment cannot exist by itself, since simply
defining a fragment is implicitly taking position on some semantics
for the fragment, thus annotating it. These semantics are most often
expressed through an annotation content. From this point of view, it
is impossible to discriminate wether having the same timecodes for 2
annotations means that they are linked or not. It depends on the
semantics of the annotations, thus the model must remain agnostic
about it.
Relation
A relation defines an ordered set of annotations. The annotations
are the members of the relation. A relation MAY also have a content.
A relation implements the Group interface for accessing its members.
View
A view can produce a rendition for a package or a package element,
possibly using elements issued from associated audiovisual medias and
resources.
Views implement the Pipeline interface and always output a resource
(see below). Views possess a content (their definition), whose MIME
type determines how the view is interpreted. The list of valid MIME
types for view definitions must be defined by applicative models.
Test
Some views may produce a content interpretable as a boolean
value. Such views can then be used to discriminate elements in a set,
they are called Tests.
Resource
A resource is composed of a content (data + MIME type). It does not
reference a specific audiovisual media, so does not strictly belong to
the annotation structure. It can be useful to build some views.
Dynamic import
Elements defined within a package are called the package’s own
elements. It is also possible to reference from within a package
elements defined by another package. These are called dynamically
imported elements (or, when there is no ambiguity, imported
elements).
A dynamic import is an element referencing, through its URL, another
package. The applicative model can specify the usable URL types. The
dynamic import element also stores, when possible, the imported
package URI.
It is possible that, when a package is shared, the defined imported
package URLs are not available for the recipient: unshared local file,
unavailable/unaccessible server, etc. It is recommended that Dynamic
import elements are enriched with metadata allowing other users to
identify the package so that they can either download or request it
an/or check that an available package is “compatible” with the one
specified by the author (the package URI is of course the first way to
check a package identity, provided it includes versioning
information). The core model does not specify this
metadata. Applicative models are strongly encouraged to specify such
metadata.
It is not required that the dynamic import structure is acyclic. It is
possible that two packages import each other. However, a package MUST
NOT have two dynamic imports to the same package, and cannot import
itself.
Constraint: the id of a dynamic import element MUST NOT contain the
colon : character, so that its elements can be correctly
addressed (see below).
Ids for dynamically imported elements
When a package dynamically imports another one, we need a way to
identify the imported package’s elements from within the importer
package. Using URIs with fragments is possible, but not always
convenient. We then propose to use the notion of identifier
reference (id-ref).
Given a package p1 defining a dynamic import i. i references a
p2 package, containing an element with the e (in the context of
p2). The e element can be identified within p2 by concatenating
the identifier of i, the colon : character, and the identifier
of e (in the contexte of p2). The obtained identifier is the identifier
reference (id-ref) of e within p1.
Example: if p1 imports p2 through an import identified with
foo, and p2 contains an a1 annotation, then the id-ref of the
annotation in p1 is foo:a1. If p2 contains an annotation
:toto:a2 (using a :toto internal prefix), it id-ref in p1 is
foo::toto:a2.
This schema can be used for multiple import levels. For instance, let
us assume that p2 imports p3 with the id bar, and that p3
contains a a3 annotation (id-ref in p3). Its id-ref in p2 is
then bar:a3, and its id-ref in p1 is foo:bar:a3.
NB1: The prohibition on using : in dynamic imports identifiers
ensures that an id-ref can be unambigously interpreted.
NB2: When the distinction between id and id-ref is not relevant, we
simply use the word “identifier”.
Direct and indirect imports
Examples presented below allow to discriminate between directly
imported element (i.e. own elements of a package imported by the
current package, for instance foo:a1) and indirectly imported
elements (i.e. elements imported by a package, itself imported by the
current package, for instance foo:bar:a1).
A constraint is that only directly imported element can be referenced
by a package’s own elements. For instance, if the p1 package from
the previous example defines a r1 relation, any own annotation of
p1 can be a member, as well as the own annotations of p2 (directly
imported in p1, through the foo dynamic import). In contrary,
the foo:bar:a3 annotation, indirectly imported by p1, cannot be
a member of the r1 relation. To solve this issue, one has to create
a direct import of p3 in p1. Concerned references include: the
media associated to an annotation, a content model, members of a
relation, list items, tag-element associations, metadata values.
Ergonomically, this limitation is reasonable and technically, it has
good properties: a directly imported element has a unique id-ref (as
opposed to indirectly imported components, which can have several). By
limiting the number of intermediaries, the risk of link breakage is
limited. Finally, we can find the URI of a directly imported element
with the available data of the package defining the dynamic import,
while it is impossible for an indirectly imported one.
Query
A query implements the Pipeline interface, and always produces a
list (see below). If a query produces items external to the package
(for instance, URLs), it has to encapsulate them in resources
(temporary, but that can be saved), so that is indeed produces a list
of package elements.
A query has a content. The MIME type of the content determines how the
query is interpreted. Le list of valid MIME types for queries must be
specified by applicative models.
List
A list is a sequence, defined by extension and ordered by the user, of package
elements (own or directly imported). Lists implement the Group interface.
Applicative models can specify a contraint integrity mechanism,
indicating which objects can belong to a list. This mechanism can use
Test views as defined above.
Tag
A Tag is an element that can be associated with any other package element
(own or imported). It allows to group a number of elements that share
a characteristic.
Applicative models can specify a contraint integrity mechanism,
indicating which objects can be associated with a tag. This mechanism
can use Test views as defined above.
Pre-defined groups
A package always possesses two pre-defined groups named own and
all. The own group contains, by definition, all elements defined
within the package. The all group contains, by definition, all
element defined and imported (directly or not) by the package. It is
consequently the union of the own group with all dynamically
imported elements.
These groups cannot be removed from the package.